Час читання: 2 хв.
Розвиток технологій штучного інтелекту вийшов на плато, що стало несподіваною новиною для багатьох. Проривні успіхи GPT-4 та його попередників могли б дати підстави для впевненості у подальших великих досягненнях, але, за даними звіту The Information , нова версія ChatGPT під кодовим ім’ям Orion показала лише незначні покращення порівняно з минулою моделлю. Очікуваний стрибок у продуктивності не виявився вражаючим, особливо в галузі програмування.
Реклама
Що ще відомо
Основною проблемою для OpenAI та інших компаній, що розвивають ШІ, стало вичерпання якісних даних для навчання. Щоб підготувати моделі, як GPT, потрібний величезний масив текстів та іншої інформації. За останні роки розробники використовували доступні дані із соцмереж та інтернет-ресурсів, таких як X (колишній Twitter) та YouTube. Однак, як тільки ці джерела були вичерпані, навчати ШІ стало набагато складніше — отримати доступ до даних, які б дозволили значно підвищити якість роботи, виявилося нелегко. Це створило вузький прохід, через який нові ШІ-моделі змушені просуватися повільніше, ніж це було раніше.
Ситуація, що склалася, веде до технічних, екологічних та економічних наслідків. Найновіші моделі штучного інтелекту, які мають сотні мільярдів або навіть трильйони параметрів, вимагають колосальних обсягів електроенергії та води. Очікується, що потреби таких центрів обробки даних зростуть приблизно в шість разів за десять років. Приклади цього вже є: Microsoft домовилася про постачання з АЕС «Три-Майл-Айленд», а Amazon та Google роблять інвестиції в атомну енергетику, щоб забезпечити ресурси для своїх центрів даних. Інфраструктура енергопостачання на рівні країн не встигає за такими запитами, що призводить до потенційної загрози перебоїв у постачанні електрики для звичайних користувачів.
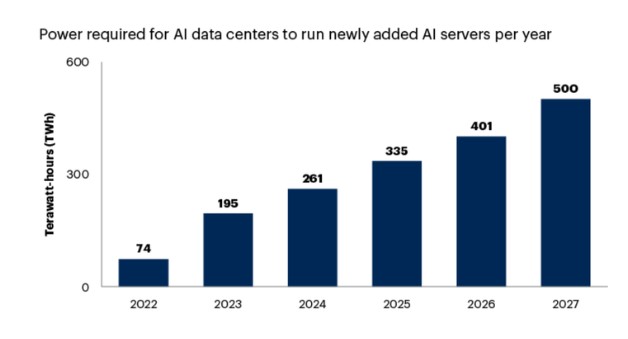
Щоб впоратися з нестачею даних для навчання та зростанням ресурсів, OpenAI почала розробляти альтернативні підходи. Одним із них може стати створення так званих синтетичних даних, коли ІІ тренують на спеціально змодельованих прикладах. Таку методику вже успішно застосовує компанія Nvidia. Крім того, OpenAI створила спеціальну команду, яка оптимізує моделі та їх розвиток на нових типах даних. Ці заходи допоможуть частково вирішити проблему, проте їх ефективність ще має бути перевірена на практиці.
Прогнози поки що не дають підстав для зайвого оптимізму. Плани з випуску Orion переносяться як мінімум на 2025 рік, і неясно, чи вдасться компанії подолати всі технічні та інфраструктурні складності на той час. Для індустрії штучного інтелекту такі зміни означають необхідність шукати нові способи навчання та розробки моделей, а також переглядати підходи до використання та розподілу ресурсів.
Загалом, незважаючи на тимчасове уповільнення, експерти вважають, що у довгостроковій перспективі ШІ-індустрія зможе адаптуватися до нових умов та продовжити свій розвиток. Такої думки дотримується і Марк Цукерберг. Цього місяця стало відомо, що він побудував найбільшу систему навчання ІІ.











