Час читання: < 1 хв.
У грудні минулого року OpenAI представила мовну модель o3, заявивши про її здатність вирішувати понад 25% складних математичних задач із набору FrontierMath — значно більше, ніж 2% у конкурентів. Однак результати незалежних тестів поставили під сумнів ці твердження та викликали дискусії щодо прозорості оцінювання моделі.
На момент презентації OpenAI акцентувала увагу на виняткових досягненнях o3 у FrontierMath. Проте минулого тижня оприлюднена публічна версія моделі продемонструвала скромніші результати. За даними дослідників з Epoch AI, які розробили FrontierMath, модель впоралася лише з 10% задач. Для порівняння, також було протестовано новішу та компактнішу модель o4-mini — наступника o3-mini.
Реклама
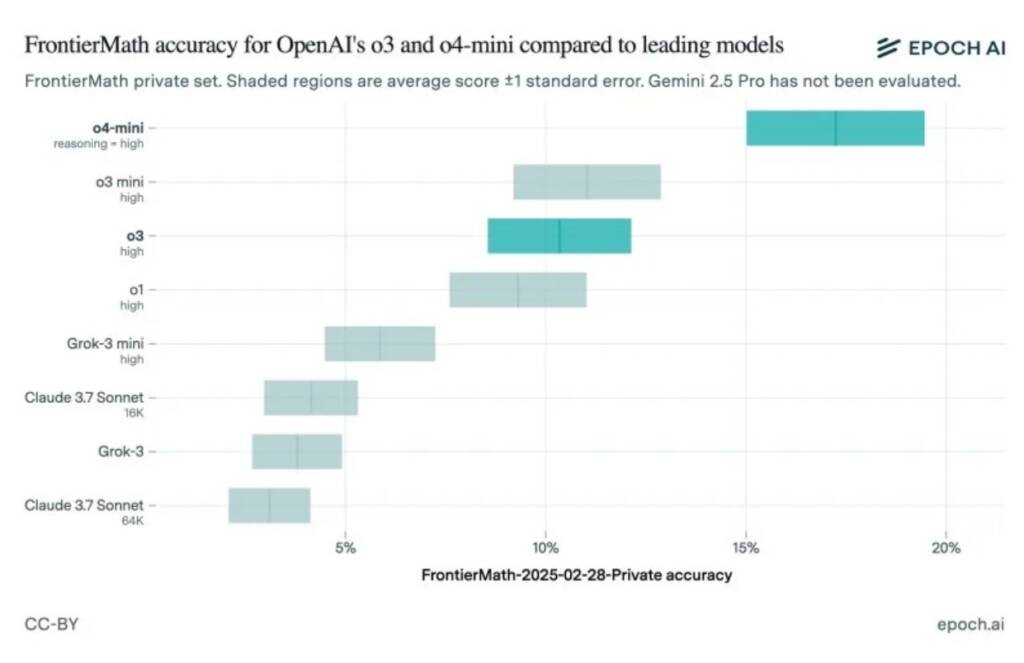
Попри розбіжність, дослідники не стверджують, що OpenAI навмисне завищувала показники. Вони вказують, що моделі могли відрізнятися, як і версії задач: OpenAI використовувала одну підмножину тесту, тоді як Epoch AI — іншу, оновлену. Також ймовірно, що OpenAI застосовувала більш ресурсну внутрішню версію моделі з більшим часом на обчислення.
Організація ARC Foundation, яка раніше тестувала o3, повідомила, що публічна версія значно відрізняється від досліджуваної ними — вона оптимізована під реальні сценарії та спрощена з точки зору обчислювальних можливостей. У компанії це підтвердили: за словами Венди Чжоу з OpenAI, публічна версія адаптована для кращої швидкості роботи, що й пояснює нижчі результати в тестах.










